Jonas is 28 years old and an aspiring heart surgeon. Some would argue that at 28, he’s still a bit young to be a heart surgeon. But Jonas has always been ahead of his time and is very talented. In his younger years, he was already present at many of his colleagues’ surgeries, was allowed to assist and already had some of these vital organs in his hands.
In fact, they were all different, but as Jonas looked closer, he saw many similarities. Well, at least they were all hearts, you might think. But let him tell us about his discovery himself:
I have always been fascinated by the most important organ in our body. The heart looks different with each person. Sometimes a little smaller, sometimes larger. Sometimes, unfortunately, the heart does not work as it should. When I looked very closely, I could even see broken hearts.
Some of the people who needed heart surgery seemed to work directly in the IT industry. Which is why I tried to find a connex.
Teams act like hearts, I thought to myself. They keep our organization, our organism, alive. Without a heart, we could not survive and so could not our organization.
Communication is like an artery through which our heart is supplied with oxygen. If our arteries are clogged, our heart doesn’t work properly either - in the worst cases we die!
Our communication, our teams and if we think it further our culture, do not only determine the survival of our organization, but wrongly treated they make us stop functioning or even ceasing to exist from one moment to the next!
 Dr. Jonas and his colleagues
Dr. Jonas and his colleagues
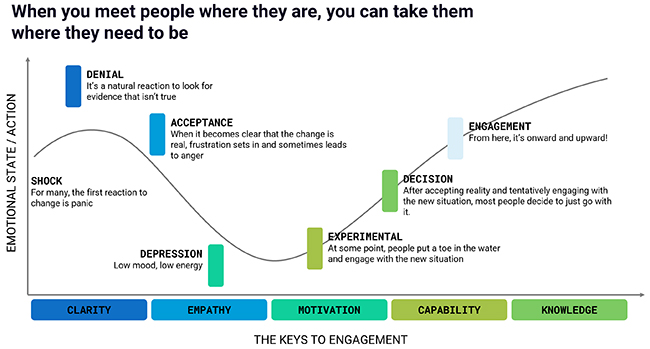
Jonas has had an uneasy feeling for some time and has been looking for answers to his thesis in the IT industry. He recognizes many hearts that are seriously ill. The COVID-19 year, with its #WFA (work from anywhere) or the change in face-to-face communication, was in some places just a drop in the bucket. He comes to one conclusion:
The IT industry is in the midst of a depression, and not just since yesterday. It has been shown to us more clearly than ever what many of us are facing.
Why is it not our highest priority to keep our heart healthy?
Heart attack - I hope not
With these findings, Jonas goes to his experienced colleagues, with whom he has always had a very good exchange and for whom the innovative views he brings in are a benefit. He shows them what he has discovered, which startles his colleagues, who thank him for this new insight. After careful consideration, his colleagues recognize a pattern:
It seems that we have put our bodies through a lot in recent years. In many IT organizations, the sinus rhythm does not seem to match the ideal, we are ailing. Have we done too little sport or been out in the fresh air too rarely? In times of Covid-19, this could well be a reason. In addition, there are the psychological burdens to which we are exposed during what feels like our 100th lockdown.
We need to save our organization from a heart attack. Constant movement and adaptation protects us from this … and of course all the good characters from Once upon a time … Life
 Once upon a time … Life
Once upon a time … Life
Keep moving
Why do we still have such a hard time adapting to change despite the agile manifesto with the value Responding to change that has been known for 20 years? Have we forgotten how to adapt? Have we become too inert and do we reflect far too rarely on what has happened? Jonas wonders why the IT pandemic is hitting us so hard. And he is not talking about the disease itself.
IT organizations today should be able to react very fast and flexible to changes in their market. A customer-centric mindset helps us significantly in this regard. But what Jonas could observe just last year is that the changes are hardly directed inwards. Working methodologies, way of working, processes, teams, communication channels … many things simply remain unchanged.
 Keep moving
Keep moving
Jonas remembers a tweet he read just a while ago. It was about a product development and the organizational goals for the next year:
C-Level to PM: We need to roll out 20 new projects this year to be successful, but the development team believes they could only focus on 2 projects at a time with the best quality. What should we do?
This did not sound at all like healthy growth to him. The correct answer to the question, as he found it, and whether this was really done in reality remains to be seen, was:
PM to C-Level: We look for the 2 projects with the highest priority, the greatest customer value and the best return on investment. And focus entirely on these projects and drop the others!
Of course, it is a major challenge to explain this situation to the C-level management, but what would be the alternative? External contractors, outsourcing projects … I hope you know where I am going with this.
- Organic growth is healthy
- Change to be able to react to market situations is good
- Intrinsic adaptation at the same speed is effective
Maybe you know similar situations or are currently in a similar job environment. In an organization that has grown very quickly and seems to struggle with structures and processes.
One body - One life
Jonas continues to reflect:
Our heart, as we know, can perfectly supply a body for years. In some exceptional cases, it is even strong enough to keep 2 bodies alive, as in the case of Siamese twins. I, as an aspiring heart surgeon, believe I can claim that this only works in certain and very special cases and only for a certain period of time.
If we now compare a delivery team in our IT organization with a body, a delivery team should, just like the heart, focus on one major topic, one business domain, one bounded context or one value stream, and master it perfectly.
This is how we create a continuous flow and master our business best. However, if a team has to serve multiple domains, or in other words, if the heart suddenly had to take over the tasks of another organ, the cognitive load in the team increases tremendously.
Hardly feasible, as Jonas feels - The focus is lost, we suffer from loss of quality. It is not one of our main objectives. Little by little, the team will slow down, the quality will move into the negative. We will pay for our misguided decisions.
Focus on excellence
If we stay with IT organizations, we talk about establishing feature teams and cross-functional teams. So we want to make sure that all the necessary skills are in a delivery team or in an extended delivery team. We are looking for motivated contributors who are not only experts in their field, but also think outside their comfort zone (T-shaped). If this alone would not be a huge challenge, there are other aspects that we must not neglect under any circumstances.
We have to take diversity into account in our teams, and thus bring different points of view into the team and, above all, we also promote creativity. We should also not disregard the different and preferably homogeneous seniority levels.
 Focus on excellence
Focus on excellence
We have to make sure that we create long-lasting teams that encourage, support and challenge each other at the right moment, always with the appropriate professionalism, but also with the highest possible trust - without trust we don’t create teams, we create waste! We want to create high-performing teams and thus a results-oriented organization.
This list is far from complete, but it should show that the composition of one or more teams and team topologies is a very complex and extensive topic.
But back to Jonas.
]]>So we now know that continuous change helps us prevent heart attacks. Furthermore, we have found that focus is an important aspect and that we need to avoid cognitive load. And we know that the way we communicate, among other things, determines success or failure.
Can we use these findings to prevent the whole thing from happening?




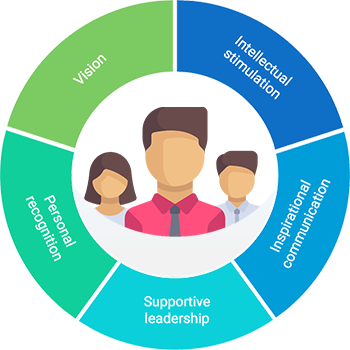 Dimensions of Transformational leadership
Dimensions of Transformational leadership